A rabbit with a tachometer in it's silhouette
When I first started using RabbitMQ I didn't understand its usefulness beyond a job queue, but it's helped me to grow and manage services architectures without headaches.
Services Architecture
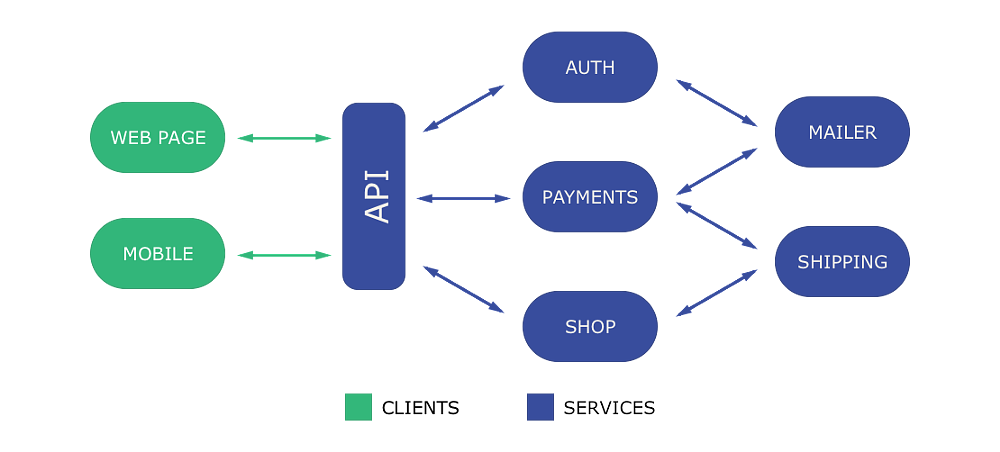
In web development, a services architecture describes a single application that consists of multiple, smaller, highly specialized, loosely coupled applications that each independently, or in tandem, solve one part of the business domain.
An example of a services architecture app
This architecture allows for parallel development of features (multiple teams can work on different services, each implementing one part of the business domain), continuous delivery of large applications without downtime (the application, as a whole, should partially work even with one service down), and the freedom to experiment and innovate on the tech stack (a service can be implemented in any technology, framework or language).
A services architecture introduces a new challenge — working with a distributed system.
Problems
The most common problem is state management or data consistency. RabbitMQ doesn't tackle this problem at all. Your application now consists of multiple smaller applications, each of which can have their own state and/or database — on which another service can rely on (e.g. a mailer service needs a user's email from an authentication service). This causes consistency issues. There are many available solutions to this problem, like CQRS, but this topic won't be covered here.
The other common problem is service discovery. You need to have a way to contact the services that compose your application — keep track of their IPs, URIs, and health. This can get out of hand if you have many services that dynamically (horizontally) scale. Traditionally this issue is solved by utilizing load balancers and service registries (like Apache Zookeeper and Consul), but RabbitMQ can partially solve this problem for us.
As the name implies, it's a message queue. Traditionally, in computer science message queues are used for inter-process communication, which can be asynchronous or synchronous. It uses AMPQ for communicating with clients — it's a wire-level binary protocol that provides mechanisms to ensure message delivery and consumption.
I was drawn to RabbitMQ because of two problems I've had while working on a project, which other message queue services didn't solve.
Some message queues don't have job execution guarantees, e.g. if a message is removed from a queue by a worker it needs to be processed no matter if the job database restarts or if the worker fails. In RabbitMQ this feature is guaranteed by AMPQ. The protocol specifies that, if desired, a message will be removed from a queue only after the consumer acknowledges it has been processed. If a consumer fails to do so in a given time frame, the message is given to another consumer.
The other problem I had with other queues was memory consumption. Some message queues keep the whole queue in memory which can bring even powerful machines to a crawl if the messages are too big or if there is too many of them. In RabbitMQ messages are kept in memory until a (configurable) threshold is reached at which point they will be written to disk. This is not true for all messages — persistent messages (those in durable queues) will be written to disk and kept in-memory as soon as they are enqueued, and there are also "lazy queues" which try to keep everything on disk and nothing in-memory (if possible).
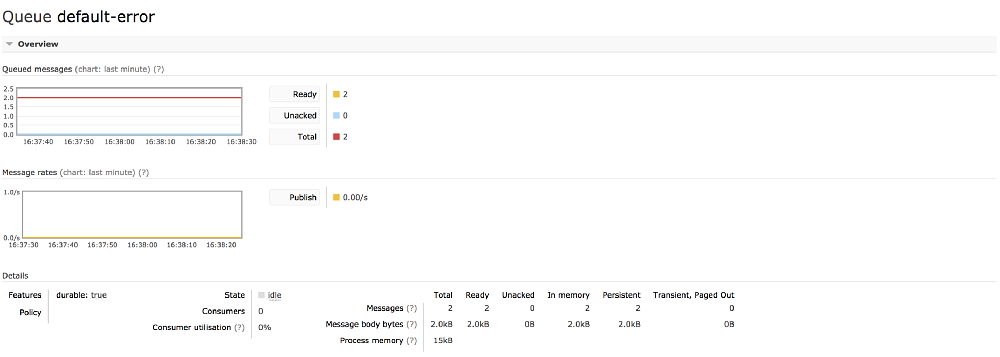
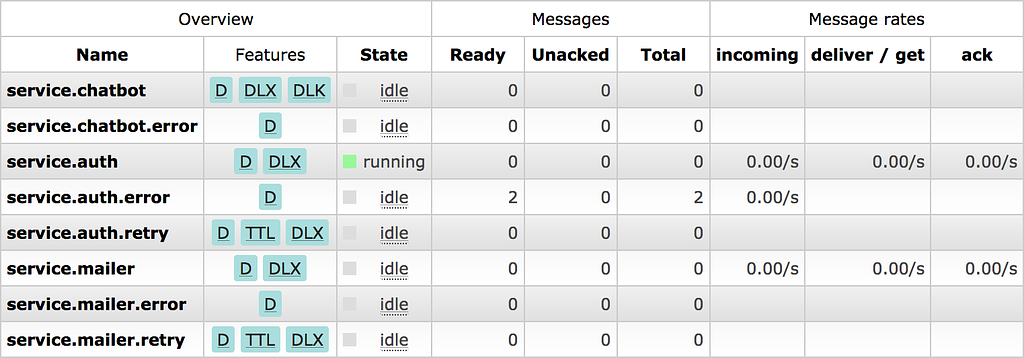
Queue statistics
RPC / Pub-Sub
Most people I've talked to aren't familiar with RabbitMQ's "direct reply-to" feature. It enables synchronous inter-process communication — you can think of it as an RPC or a Pub-Sub interface. With it, any client can send a message to any queue and get a direct response from any consumer processing messages in that queue. The same rules of memory usage and persistence as described before apply, but message loss protection is not guaranteed with this mechanism.
In my opinion, this method of inter-process communication is better than building your services as HTTP servers. With HTTP servers you re-implement logic that is already present in message queues — e.g. success and failure responses, timeouts, and routing. Oftentimes HTTP servers come with unnecessary overhead for a services architecture like some middleware, session storage and encryption mechanisms which can slow the whole application down. With AMPQ and RabbitMQ you only need to implement your business and serialization logic (in what format will the messages be written to the queue).
Exchanges
In AMPQ, messages aren't published directly to queues, but to exchanges. Exchanges are routers (or post offices) that determine which queues (more than one!) should receive a message.
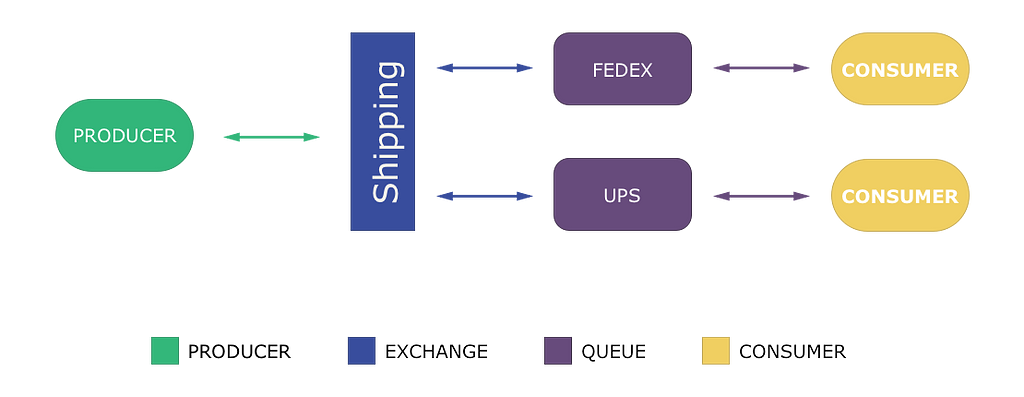
Topic exchange example
RabbitMQ supports four types of exchanges — direct, fan-out, topic and headers.
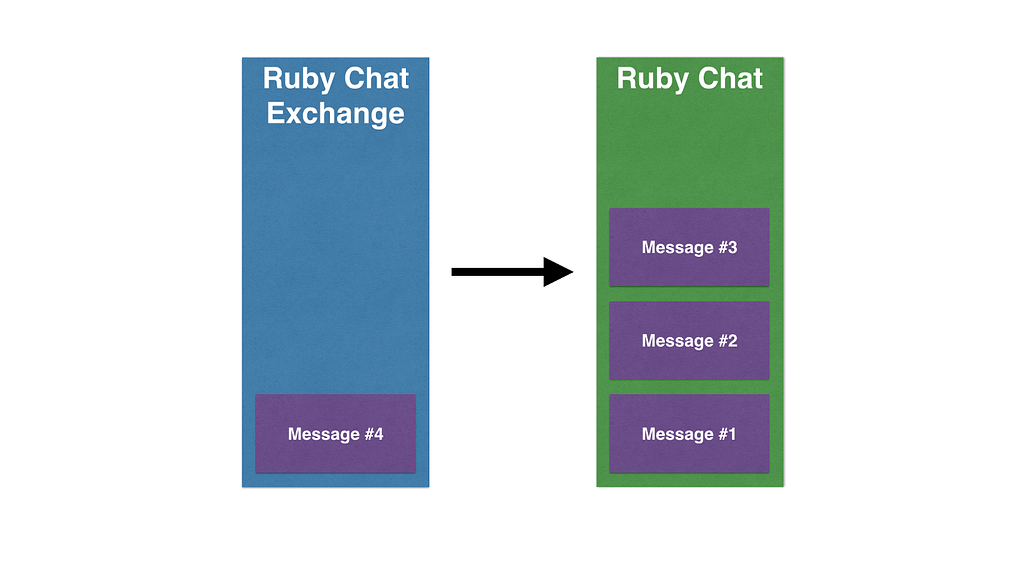
Direct exchange example
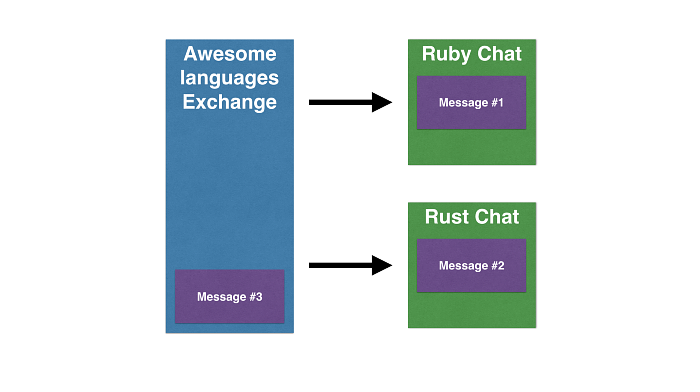
Direct exchanges deliver messages directly to a single queue, e.g. when you don't want to use exchanges and just want to deliver a message to a queue. For example, if each chat room of an application is represented by a queue, a Ruby Chat Exchange would deliver messages only to the Ruby chat queue.
Fan-out exchange example
Fan-out exchanges deliver messages to all queues bound to them. You can think of them as groups, a message sent to the group will be delivered to all queues in the group. With the previous chat example, a fan-out exchange can be imagined as a broadcast to select channels. E.g. if we want to send a messsage to all chats of awesome languages we can publish a messsage in the Awesome languages exchange which would deliver those messages to both Ruby and Rust chats.
Topic exchange example
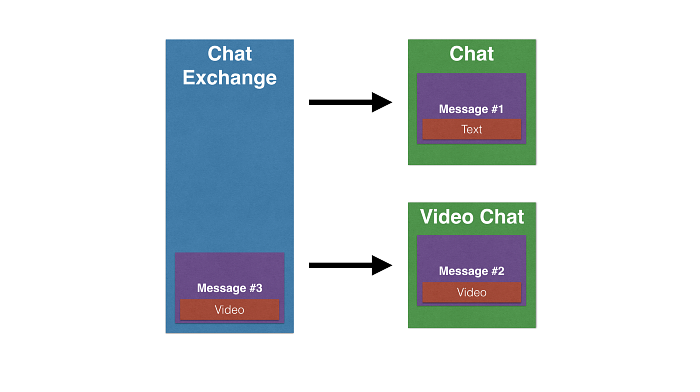
Topic exchanges deliver a message to queues tagged with a topic (the above image is an example of such an exchange). E.g. if a message has a routing key (tag) of "Fedex" and it's delivered to the "Shipping" exchange it will be delivered to the "Fedex" queue. Or, with our chat example, a message tagged with text would get delivered to the Chat queue, while a message tagged video would get delivered to the video queue.
Lastly, header exchanges are an continuation on the idea of topic exchanges, they can take different properties of the message being delivered to determine where it should be delivered.
Exchanges come with a multitude of features — dead-lettering (if a message isn't acknowledged or was rejected it gets sent to another exchange), alternate exchanges (a client can specify an exchange to which a message gets routed if the primary exchange rejects it), priority consumers (the ability to specify which consumers to prefer, e.g. consumers on more powerful machines), priority queues (messages can be assigned a priority, higher priority messages get processed first), TTLs (specifies how long a message or queue "lives", though this feature has a caveat — please refer to the manual before using it), and others.
They are not only useful for offloading message delivery logic from your services off to RabbitMQ, but also serve as a way to deprecate services, and reduce downtime. If a service is to be deprecated, its messages can be routed to another service that knows how to process them, or that returns errors interpretable by other services as responses. If a new version of a service is about to be deployed an exchange can be configured to deliver messages simultaneously to the old service's and the new service's queues. Or, when the new service is up, all incoming messages can be redirected to it.
Service discovery
Since RabbitMQ supports multiple producer and multiple consumer queues, exchanges can be utilized as a form of service discovery. Each service knows its name and the names of the services it depends on, therefore it only has to publish messages on their exchanges (or fail if an exchange doesn't exist), and listen for messages on its queue.
List of available queues
For small services architectures this kind of service discovery is sufficient. All services will communicate through RabbitMQ, and therefore we are able to keep track of them. But sometimes the need arises to communicate with other applications that don't use AMPQ, or keep track of applications in a cluster (e.g. for databases, or RabbitMQ instances) — this kind of service discovery is not suitable for those use-cases and should be handled with the like of Consul or Zookeeper.
Plugins
Personally, I find this to be the "killer feature" of RabbitMQ. If RabbitMQ is missing any kind of functionality you desire it can be added. Out-of-the-box it comes with quite a few useful plugins.
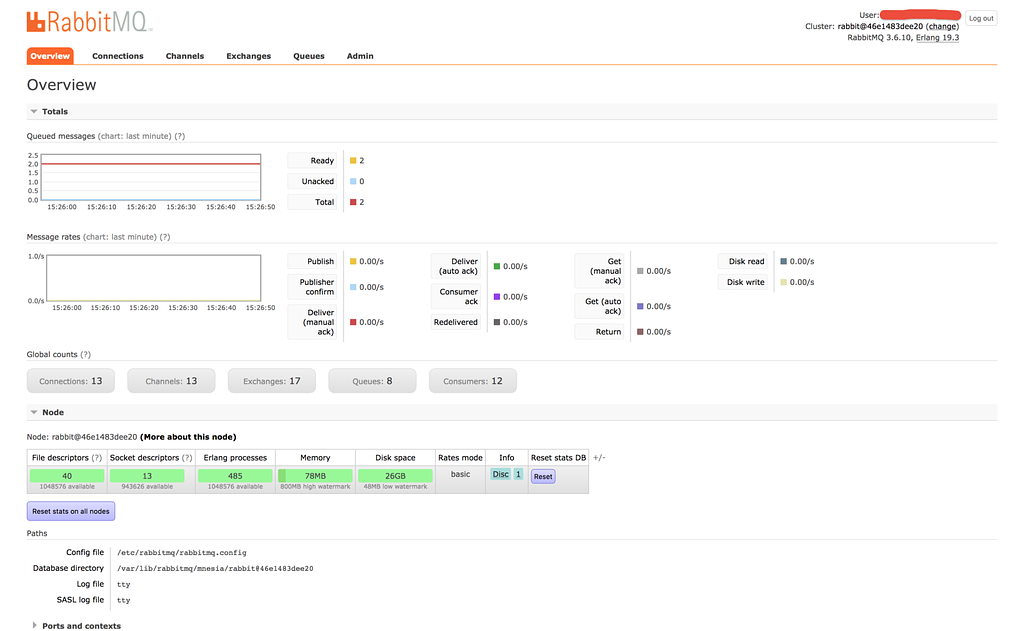
The one plugin I use most often, and the first plugin I introduce people to is the Management plugin. It gives RabbitMQ a full user interface through which you can configure and monitor individual exchanges and queues, monitor system performance, memory and disk usage.
Overview panel in the Management plugin
Through plugins RabbitMQ can support competing protocols to AMPQ — like MQTT, STOMP and WebSockets.
And while clustering is supported, the Federation plugin brings it to a new level. It enables message passing between brokers without clustering (useful since RabbitMQ requires IP addresses of the other instances, instead of URIs, when clustered). E.g. multiple clusters of RabbitMQ can exchange messages between each other. An useful analogy would be Mastodon's and Diaspora's federations which allow users on different instances to communicate as if they were on the same instance. It also comes with a UI that's accessible through the Management plugin.
Lastly, there is a feature called "firehose" that logs all internal messages of RabbitMQ. It's extremely useful for debugging plugin behavior, exchange configuration and even just for logging.
Conclusion
RabbitMQ has helped me manage and scale my services architectures by utilizing plugins, exchanges, queues and the RPC interface. It's become an essential tool for building services.
My biggest issue now is my dependency on it — it's become the backbone of my services architectures. This introduced a large single point of failure, but it's manageable with the Federation plugin and clustering.
If you are struggling with the limitations of your queue service, clustering or inter-process communication — try RabbitMQ. It excels at all those tasks and brings many utilities that can prove helpful for managing your application.
If you are struggling to introduce RabbitMQ to your project. Try it as a simple queue first, and then slowly move more and more services to it